Hi there!
In this post I will describe what is a Bloom Filter, its purpose and scenarios where it can be useful to use one. I will also implement a Bloom Filter from scratch in Python, for an easier understanding of its internals.
Goal of a Bloom Filter
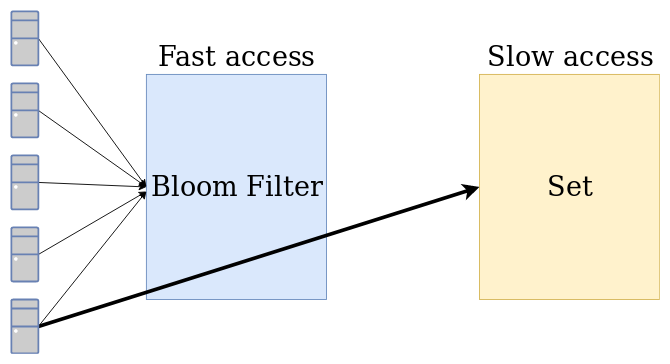
A Bloom Filter is a data structure with the goal of checking if an element is NOT in a set in a fast way (for those who know Big O notation, the complexity of inserting and checking if an element belongs to a set using a Bloom Filter is O(1)). It can be very useful to prevent a computation-intensive task to be done often, simply by verifying if the element is definitely not in a set. It is important to understand that the Bloom Filter is a probabilistic data structure: it can tell you that an element is not in the dataset with 100% probability, but it cannot tell you that an element is in the set with 100% probability (false positives are possible). Let’s talk about scenarios where a Bloom Filter can be used, and later on you will understand why the Bloom Filter has these characteristics, with a detailed explanation of its internals and an implementation in Python!
Scenarios
Let’s think of some scenarios where such data structure can be useful to speed up the computation of some tasks. We can start by thinking in a router of a core network (those that you don’t have in your house :) ). It can be required for those routers to have an uplink speed of over 100 Gbit/s. The administrator can add a blacklist of IPs to block their access in the network. That means that everytime that the router receives a packet, at over 100 Gbit/s, it must look at his memory and perform, at best, a logarithmic search (O(log(n))) to check if the IP is blocked, knowing that most IPs are not blocked and that the search will not return any results for most packets. In this case, a Bloom Filter can be placed before the access to memory, to make sure that most packets do not need to wait the time of a search of an IP to be sent to the network.
Another scenario is the database example. When a database has millions of accesses per second, and most of the accesses are searches by a key that is not in the database, it can be important to reduce the impact of the calls on the database, for two reasons: if the number of searches is reduced, the database engine will reply faster to other accesses; if it is possible for a client to not wait for a search on the database and have the result (e.g. not in memory) without needing to access the database, the achieved speedup can be significant.
Finally, to speed up the search for a file in a folder with many files, the Bloom Filter can be used to check if the file is definitely not in the folder.
More typical scenarios of usage of a Bloom Filter can be found here.
What is a bloom filter?
Let’s use the first scenario to exemplify the construction of a Bloom Filter. Imagine that you blacklist 100 IP’s. The easiest way to mark if an IP was blacklisted or not is to create a list with 100 bits, each bit is one IP. If an IP is blacklisted, we mark the position of the IP as ‘1’, otherwise is ‘0’.
How many IP’s there are?
This implementation works… if only 100 IP’s are used. In reality, each IPv4 address has 32 bits, which means that there are 4 294 967 296 (232) possible addresses (some of them are reserved for private networks, broadcast, multicast and other special networks, but it is still a huge number)! And the number of blacklisted IPs will probably not exceed the hundreds, at maximum. We cannot afford to construct a list so large to use only a reduced number of entries. We have to find a mapping between an IP and an entry of a list. And that’s where hash functions come in!
Hash Function
A hash function is a function that transforms an input of arbitrary length into a fixed-size value. In that way, we can create an array with fixed size and calculate the output of a hash function given an IP, and it will always generate a number smaller or equal to the size of the array. The hash function is not random, which means that for the same input, the output will always be the same.

But wait… Something is not right. Let’s go back to our scenario. Imagine that we blacklist 100 IP’s. How does the hash function maps our 100 IP’s from a possible 232 IP’s to 100 different values without storing any information from them? The truth is that it doesn’t. There will be collisions. The hash function guarantees that each IP will have a unique mapping to a number, but since there can be 4 294 967 296 (232) possible IP’s, it’s impossible to map them all to 100 different values. All the hash function can guarantee is that it scrambles the bits of the input such that the output follows a uniform distribution. This means that if you change the input of the hash function from 192.168.1.1 to 192.168.1.2, the output will probably be totally different, seemingly random (but not truly random, since each input will always map to the same output).
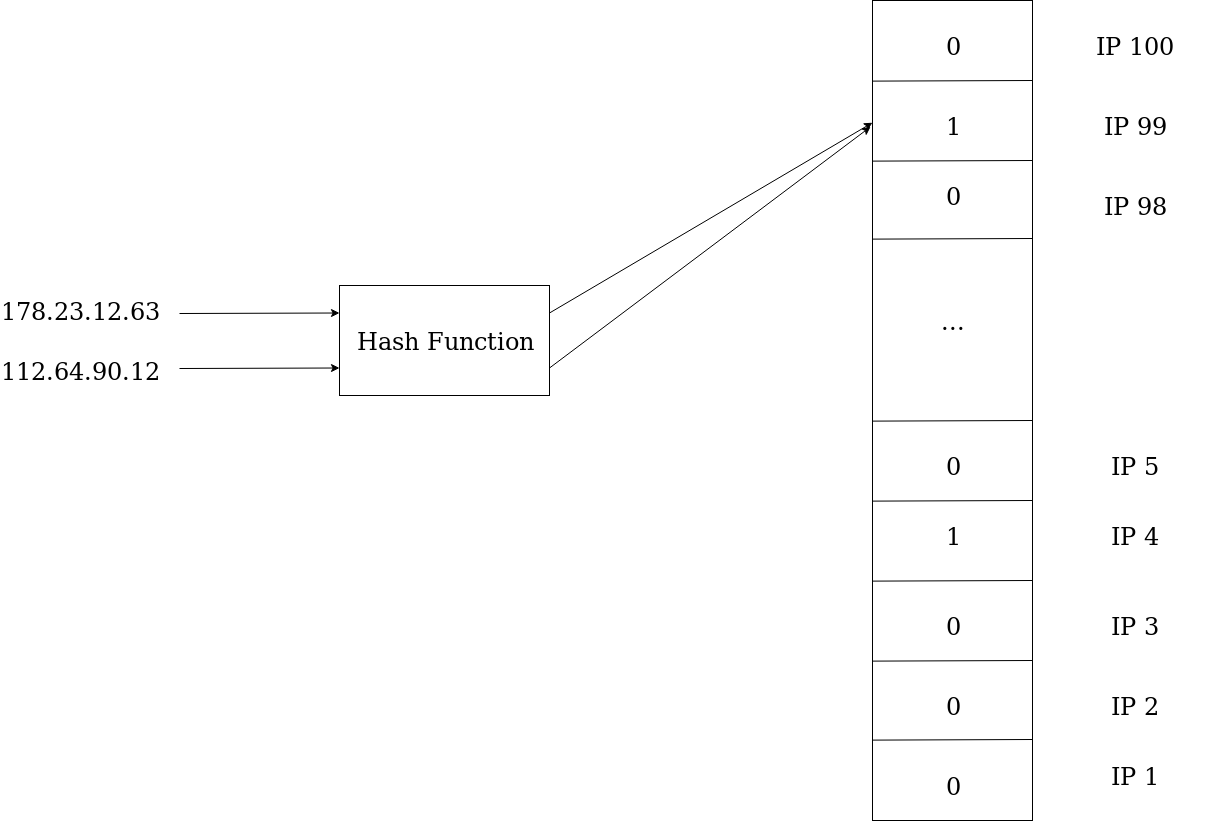
Alright, now from the beginning: we blacklist 100 IP’s. Each IP will go through the hash function, and the result of the hash function will return a number smaller or equal to the size of the array. That number will be the index of the array that marks if the IP was blacklisted or not. But there will be collisions, so how do we handle that?
Let’s suppose that the IP’s 178.23.12.63 and 112.64.90.12 have the same hash. The first IP was blacklisted, the second was not. When we check if the hash of the second IP is in the Bloom Filter, it is, even though the IP was never blacklisted. Does this mean we have a bug?
Remember that in the beginning I said that the Bloom Filter has the goal of checking if an element is NOT in a set. If the position of an element in the Bloom Filter is 0, that element is definitely NOT in the set. However, if the position of an element in the Bloom Filter is 1, that element may be in the set, or it may be just a collision. All we can do is to reduce the probability of a collision, to reduce the number of times that the a memory access is needed to check if the IP is really blacklisted.
Reducing the collision probability
There are two main ways of reducing the probability of a collision, both at a cost. One possibility is to increase the size of the array. If we increase the size of the array (and consequently make the hash function return a number smaller or the same size as the new array size), the possibility of collisions decreases. Specifically, the probability of a false positive (the Bloom Filter return 1 when the element is not in the set) is (1-e(m/n)), where m is the number of elements expected to insert in the filter and n is the size of the filter.
Other way to reduce the probability of a collision is to increase the number of hash functions. This means that in our scenario, for one IP, various hash functions will be used to encode that IP, and various locations in the array will be marked with 1. If we use k hash functions, the probability of a false positive is now (1-e(mk/n))k, which means that the optimal number of hash functions is (n/m)*ln(2) (more details about the equations here).

Let’s implement a Bloom Filter in Python in just around 50 lines of code and see the result!
In the next snippet of code, let’s start by creating a BloomFilter class. The constructor receives the size of the Bloom Filter and, optionally, the number of expected elements that the bloom filter will store. We will use the bitarray library to create an array of bits, and we set them all to zero. Finally, we set the number of hash functions to the equation that returns the optimal number of hash function, given the size of the bloom filter and the number of expected elements.
import math
from bitarray import bitarray
class BloomFilter(object):
def __init__(self, size, number_expected_elements=100000):
self.size = size
self.number_expected_elements = number_expected_elements
self.bloom_filter = bitarray(self.size)
self.bloom_filter.setall(0)
self.number_hash_functions = round((self.size / self.number_expected_elements) * math.log(2))Now let’s define a hash function for the Bloom Filter. The implementation used (from here) implements the DJB2 algorithm. Let’s use it as a black box, since the explanation of the algorithm is beyond the scope of this post.
def _hash_djb2(self, s):
hash = 5381
for x in s:
hash = ((hash << 5) + hash) + ord(x)
return hash % self.sizeNow we have on hash function, but how do we create K hash functions? We can perform a simple trick that works. Instead of creating different hash functions, we will just append a number for each input in the hash function. The number will represent the hash function number that is being called. Because any small difference in the input of a hash function will result in a totally different hash, the result can be seen as a different hash function. Cool, right?
def _hash(self, item, K):
return self._hash_djb2(str(K) + item)Now let’s create a function to add an element to the Bloom Filter. For that, let’s iterate through all of the hash functions, calculate the hash for the item and finally put a 1 (or True) in the index of the hash.
def add_to_filter(self, item):
for i in range(self.number_hash_functions):
self.bloom_filter[self._hash(item, i)] = 1The only thing that’s left is to create a function that checks if the element is NOT in the Bloom Filter. For that, let’s iterate again through all the hash functions. If any of the Bloom Filter positions has 0, we can say that the element is definitely not in the set. Otherwise, if all positions have 1, we cannot say that the element is not in the set.
def check_is_not_in_filter(self, item):
for i in range(self.number_hash_functions):
if self.bloom_filter[self._hash(item, i)] == 0:
return True
return FalseAnd that’s it! We have implemented our Bloom Filter. Let’s try it out!
Let’s create a simple test to check if it is working. Let’s create a Bloom Filter with 1 million entries, and then set the expected number of elements to 100 000. We are going to add the element “192.168.1.1” to our Bloom Filter as the blocked IP.
bloom_filter = BloomFilter(1000000, 100000)
base_ip = "192.168.1."
bloom_filter.add_to_filter(base_ip + str(1))To test it, we will iterate from 1 to 100 000, and check if the IP 192.168.1.i is in the Bloom Filter (there are no IP’s when i>254, e.g. 192.168.289, but in this case we are just performing a test). We will print the elements that we don’t know if they are in the set; all other elements that will not be printed are definitely not in the set.
for i in range(1, 100000):
if not bloom_filter.check_is_not_in_filter(base_ip + str(i)):
print(base_ip+str(i))192.168.1.1
Wow! Our Bloom Filter says that, from 100 000 IP’s, the only element that could be blocked is really our blocked IP! It did not produce any False Positive!
Here is the full code of our Bloom Filter:
import math
from bitarray import bitarray
class BloomFilter(object):
def __init__(self, size, number_expected_elements=100000):
self.size = size
self.number_expected_elements = number_expected_elements
self.bloom_filter = bitarray(self.size)
self.bloom_filter.setall(0)
self.number_hash_functions = round((self.size / self.number_expected_elements) * math.log(2))
def _hash_djb2(self, s):
hash = 5381
for x in s:
hash = ((hash << 5) + hash) + ord(x)
return hash % self.size
def _hash(self, item, K):
return self._hash_djb2(str(K) + item)
def add_to_filter(self, item):
for i in range(self.number_hash_functions):
self.bloom_filter[self._hash(item, i)] = 1
def check_is_not_in_filter(self, item):
for i in range(self.number_hash_functions):
if self.bloom_filter[self._hash(item, i)] == 0:
return True
return False
bloom_filter = BloomFilter(1000000, 100000)
base_ip = "192.168.1."
bloom_filter.add_to_filter(base_ip + str(1))
for i in range(1, 100000):
if not bloom_filter.check_is_not_in_filter(base_ip + str(i)):
print(base_ip+str(i))And that’s it for Bloom Filters! I hope that you have learned what a Bloom Filter is in detail and how to implement it.
Thanks for sticking by!