
Hi there! Have you heard about eBPF? eBPF is not a new technology, but its usage has been growing in some areas, such as network security, network observability and performance monitoring. However, the implications of allowing users to run user code in kernel space can have a much wider impact than just in those areas. Let’s find out how it works!
To understand eBPF, we must first understand what is the kernel space and the user space in an operative system. The user space is where most programs run. The kernel space is where the OS runs. The kernel space has privileged access to hardware, such as devices, file access and networks. That’s why device drivers usually run on kernel space. However, if a program on the kernel breaks, it can break the whole OS, so most programs run in user space.
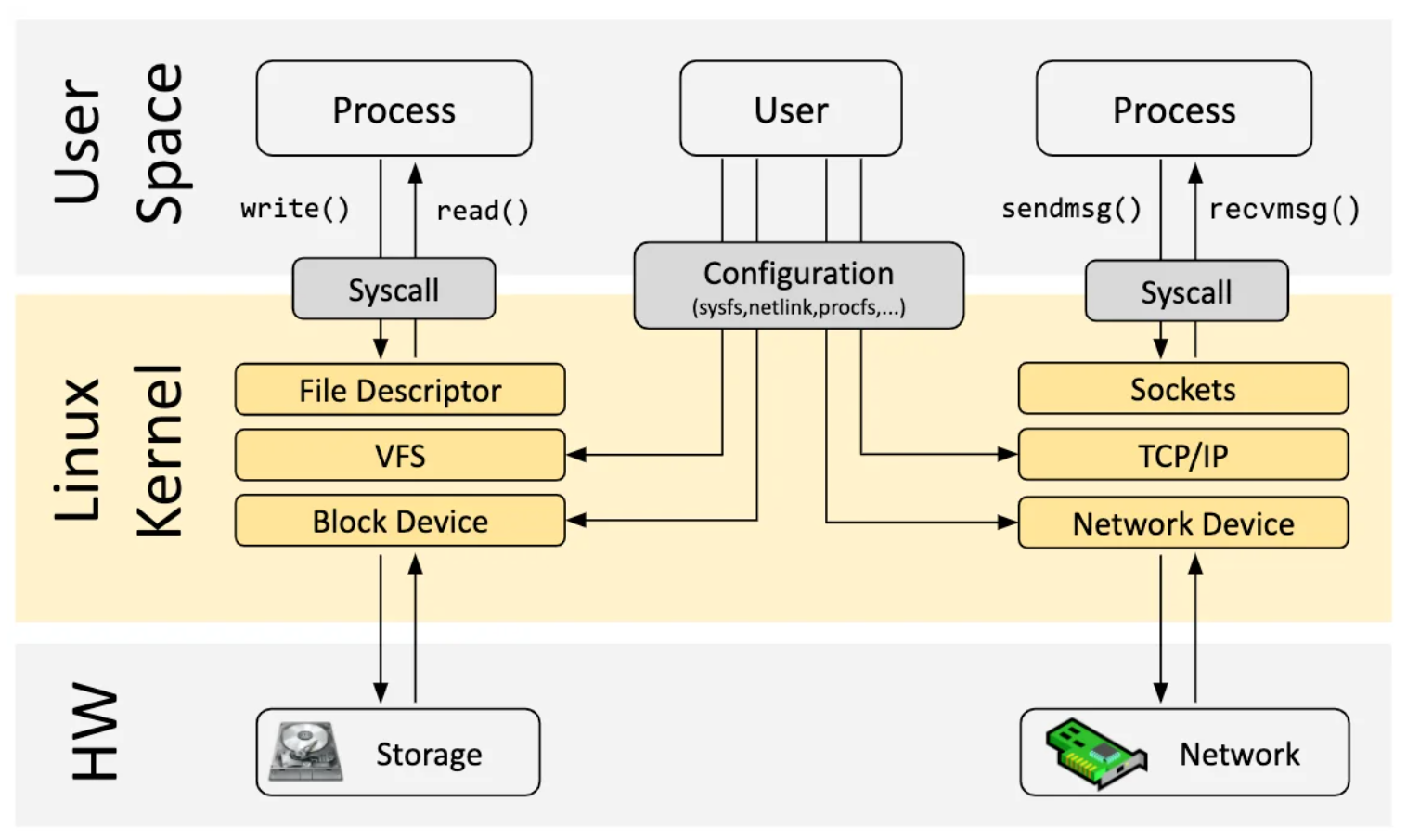
When a program runs on the user space, it can interact with the kernel space through an API - the system calls. If a program wants to write to a file, it does not need to access the underlying memory directly; in a similar case, if a program wants to send packets over the network, it does not access the network controller directly; instead, it relies on the system calls, that expose an abstraction of the resources.
While the system calls allow for the OS to expose an abstraction of the resources, they also limit what is possible to do with them. A program interaction with the hardware is limited by the operations available through the system calls. Sometimes the system calls can even be slower than accessing the hardware directly. Each system call has a performance penalty of crossing the user/kernel space, and if an application in the user space requires access to the kernel space often, its performance can be heavily penalized.
For those reasons, it may make sense to run a program in the kernel space. You have mainly two options to do that: firstly, you can request to add your code to the Linux kernel. This option can take years to be accepted and released to the general public, but makes sense if your program is useful to the kernel of the OS. Secondly, you can use eBPF.

BPF (Berkeley Packet Filter) is a kernel program that filters packets before they are read by the kernel. This is done with a small virtual machine that can be programmed by applications in the user space. Using BPF, you can perform packet filtering in an extremely efficient way, with the tradeoff of being limited by a small instruction set defined by BPF.
eBPF (extended BPF) is mainly an extension of the instruction set of the original BPF, with custom data structures (maps), helper functions, and tail calls, among others. With the new extension set, eBPF is not limited to networking use cases such as packet filtering, but can allow to trace and manipulate kernel function calls, syscalls, and other system events.
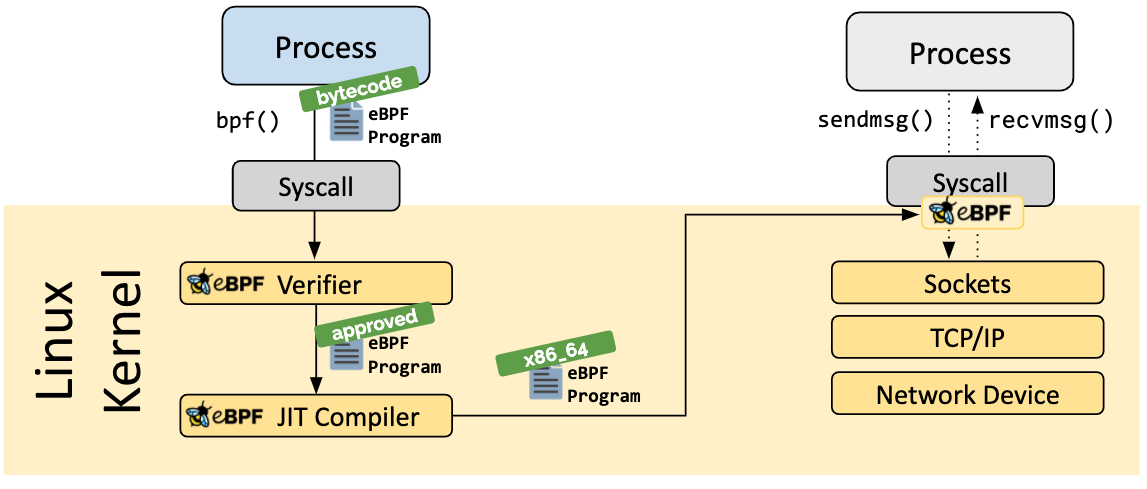
In this way, you can code your program from the user space to be run in the kernel space, at runtime, and sandboxed.
As code is being run in the kernel space, additional measures must be taken to ensure that the code does not introduce problems in the kernel. eBPF performs security checks on the bytecode before loading it into memory, ensuring some problems do not happen, such as memory out-of-bounds. Many features in the virtual machine that can pose security risks or that may expand the attack surface are also disabled by default.
With these innovative features, eBPF is now used widely in data centers of large companies, such as Facebook, Google or Netflix, with a focus on network monitoring, performance monitoring, or network observability.
Let’s implement a simple program using eBPF. The program will monitor the deleted files in the system and print their filename.
To do that, we will use the eunomia-bpf tool to help us with the development. The eBPF program is the following:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
char LICENSE[] SEC("license") = "Dual BSD/GPL";
SEC("kprobe/do_unlinkat")
int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name)
{
pid_t pid;
const char *filename;
pid = bpf_get_current_pid_tgid() >> 32;
filename = BPF_CORE_READ(name, name);
bpf_printk("KPROBE ENTRY pid = %d, filename = %s\n", pid, filename);
return 0;
}
This code is from the eunomia tutorial. As you can see, the eBPF code is very similar to C. In reality, eBPF programs are written in a restricted subset of C.
eBPF allows the user to write programs (probes) to execute before or after a system call is handled. In this case, we are defining a probe (kprobe/do_unlinkat) that executes before the system call do_unlinkat is executed. This system call is called when a file is deleted. Almost all functions in the kernel can be probed, including system calls or interrupt handlers.
The function takes as parameters the file descriptor and a pointer to the name of the file being removed. In the code, we retrieve the PID of the process executing the system call and the filename, and print them in the kernel log.
The kernel log can be accessed in the file /sys/kernel/debug/tracing/trace_pipe.
Let’s compile and run the program using the ecc tool.
> ./ecc kprobe-link.bpf.c
INFO [ecc_rs::bpf_compiler] Compiling bpf object...
INFO [ecc_rs::bpf_compiler] Generating package json..
INFO [ecc_rs::bpf_compiler] Packing ebpf object and config into package.json...
> sudo ./ecli run package.json
INFO [faerie::elf] strtab: 0x4f9 symtab 0x538 relocs 0x580 sh_offset 0x580
INFO [bpf_loader_lib::skeleton::poller] Running ebpf program...
Now that the program is running, let’s create and delete a file.
> touch toBeDeleted
> rm toBeDeleted
Finally, let’s see what is in the output file.
> sudo cat /sys/kernel/debug/tracing/trace_pipe
<...>-7727 [001] ....1 867.906922: bpf_trace_printk: KPROBE ENTRY pid = 7727, filename = toBeDeleted
There may be many log lines, but you should find the indication of the file you just deleted.
If you’re curious, play other applications and see which files they remove. You may be surprised!
Probes are just a single feature of many in eBPF, so if you want to explore more, follow other tutorials from Eunomia.
As you can see, probing a system call from the user space would not be possible without eBPF. eBPF opens up a lot of possibilities for exploring the kernel space like it was not possible before. For programs that must interact with the low-level details of the operative system, such as file access, networking processes, hardware access, or other kernel operation, eBPF is a great tool to have under your belt.
Thanks for reading!