
Recently, I wrote two articles in Engineering Talkdesk Blog, about Word Embeddings and Sentence Embeddings. In this series of three blog posts, I will explain in detail some of the approaches described to obtain Sentence Representations.
In this first part, I will explain how to represent a word numerically and how to represent a sentence numerically using the TF-IDF algorithm.
Obtaining Word Representations
How do we represent a word?
The simplest way to represent a word is with a one-hot encoded vector. Let’s imagine we have a vector with the size of the vocabulary, where each entry corresponds to a word (Figure 1). In that way, the representation of each word is a vector of zeros, with ‘1’ in the position of the word. However, this representation has some disadvantages.
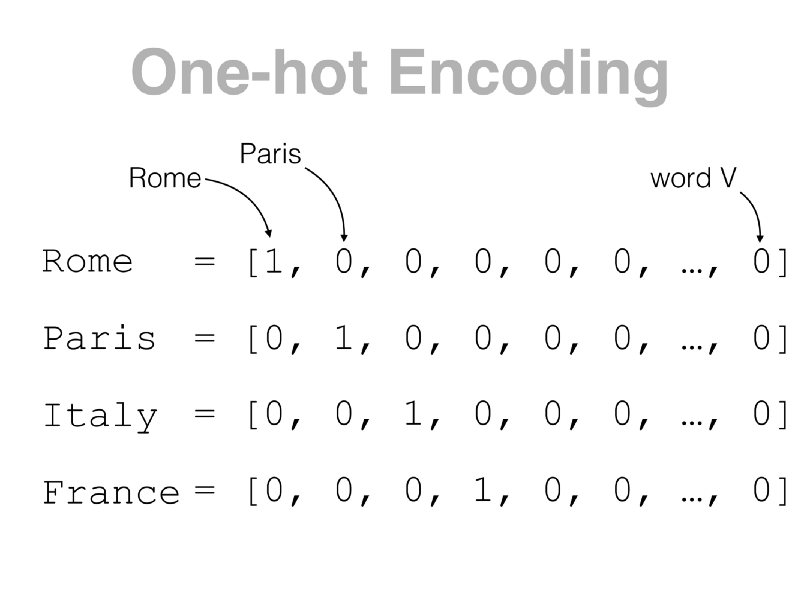
The representation of each word is very high-dimensional (a vector with the size of the vocabulary) but sparse (only one entry has the value ‘1’).
This does not provide much information about the word meaning, and it does not reveal any existing relationship between words. The representation of the word “Rome” is as close to the representation of the word “Paris” as any other word in the corpus, because their representations always differ in the same way. All other positions are the same with exception to the position of the word “Rome” and the position of the other word.
Another representation currently used is Word Embeddings (Figure 2). An embedding is a low-dimensional space that can represent a high-dimensional vector (such as the one-hot encoding of a word) in a compressed vector.
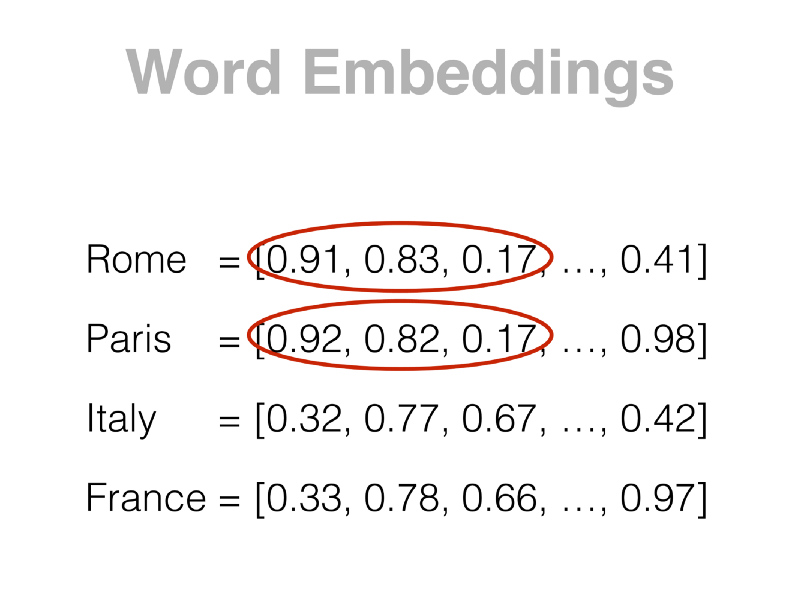
Besides the higher density of those vectors, the advantage of the embeddings is the closeness between similar words. That means that words such as “Rome” or “Paris” will probably have a similar embedding, different from the embedding of “Internet”, for example. That is very useful for many other Natural Language Processing (NLP) tasks, such as word clustering or topic analysis.
Obtaining Sentence Representations with TF-IDF
To represent sentences, it is impossible to create a one-hot encoding schema: there is an infinite number of sentences. We have to use other kinds of sentence representations.
We are going to explain four different sentence representation algorithms in this blog series. For this post, let’s learn more about TF-IDF!
TF-IDF (Term Frequency-Inverse Document Frequency) is a classical information retrieval method, commonly used by search engines, where the goal is to quickly search documents in a large corpus. Those documents can be sentences, dialogues or even long texts.
TF-IDF creates a term-document matrix (Figure 3), where each term has associated all the documents where it appears, and a weight for each term-document entry. The weight of a term in a document increases with the number of times that the term appears in that particular document, and decreases with the frequency that the term appears in all documents. In that way, terms such as “a” or “the” in an English corpus will have lower weight because they appear in many documents.
A training corpus (set of documents) must be used to create the TF-IDF matrix. The dimensions of the matrix will be the number of different terms in the corpus by the number of documents in the corpus.
The representation of a document is calculated by comparison with the documents in the training corpus.
The document representation will be a row vector with the size of the number of documents in the corpus, where each entry i will have a value that represents the similarity of the input document with the document i in the corpus (Figure 4).
That similarity is calculated based on the terms mentioned both in the input document and in each document in the corpus. A higher weight in the the entry i of the document representation means that there is a higher similarity with the document i in the corpus.

Document representations based on TF-IDF have some advantages:
- They can be calculated very fast, with a lookup on the TF-IDF matrix and a few simple calculations.
- They are conceptually simple when compared with other algorithms.
- Their implementation is transparent and the representation can be easily understood.
Their disadvantages are the following:
- The similarity between documents does not take into account the position of each word in the document (also known as a bag-of-words model).
- It does not capture the semantics of a document, which means that it does not take into account similar words.
- It creates sparse vectors, which means that it is wasting a lot of memory with zero values.
And that’s it for the first post! Read part 2 to know more about more advanced approaches to create Sentence Embeddings.
Thanks for sticking by!