
Hi there! This post is the second in a three-part series about Sentence Embeddings. If you didn’t read part 1, you can find it here.
In this post, I will explain two approaches to create Sentence Embeddings: Doc2vec and InferSent.
To improve the sentence representations from the TF-IDF representations, we must take into account the semantics of each word and the word order. Sentence embeddings try to encode all of that.
Sentence embeddings are similar to word embeddings. Each embedding is a low-dimensional vector that represents a sentence in a dense format. There are different algorithms to create Sentence Embeddings, with the same goal of creating similar embeddings for similar sentences.
Doc2vec
The Doc2vec algorithm (or Paragraph Vector) was proposed in 2014 by Quoc Le and Tomas Mikolov [1], both Research Scientists at Google at the time. It is based on the Word2vec algorithm, which creates embeddings of words. The algorithm follows the assumption that a word’s meaning is given by the words that appear close-by.
You shall know a word by the company it keeps (J. R. Firth 1957)
The authors present two variations of the algorithm: the Distributed Memory model (DM) and the Distributed Bag-Of-Words (DBOW).
Distributed Memory Model
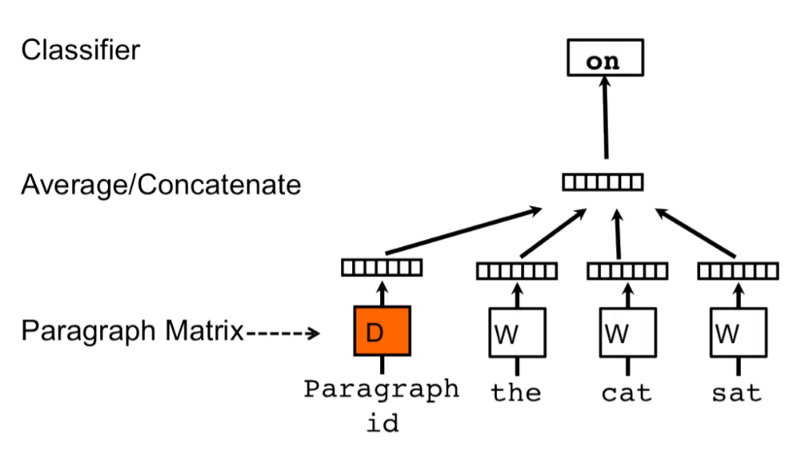
In Figure 1, a Neural Network architecture for the DM model is depicted. Let’s start by analyzing the training stage, and then we will see how the model creates an embedding for a sentence.
Each sentence and each word in the training corpus are converted to a one-hot representation. Both will have an embedding, stored in the matrices D and W, respectively. The training is done by passing a sliding window over the sentence, trying to predict the next word based on the previous words in the context and the sentence vector (or Paragraph Matrix in the figure). The classification of the next word is done by passing the concatenation of the sentence and word vectors into a softmax layer. The word vectors are the same for different sentences, while the sentence vectors are different. Both are updated at each step of the training phase.
The prediction phase is also done by passing a sliding window over the sentence, trying to predict the next word given the previous words. All the weights of the model are fixed, with exception to the weights of the sentence vector, that are updated for every step. After all the predictions of the next word are computed for a sentence, the sentence embedding is the resultant sentence vector.
Distributed Bag-Of-Words Model
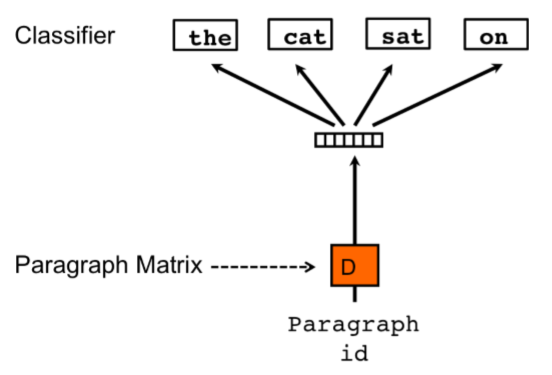
Figure 2 shows the Neural Network architecture for the DBOW model. This model ignores the word order and has a simpler architecture, with fewer weights to be learned.
Each sentence in the training corpus is also converted into a one-hot representation. The training is done by, on each iteration, selecting a random sentence from the corpus and, from that sentence, selecting a random number of words. The model will try to predict those words based only on the sentence ID, and the sentence vector will be updated (in the Figure, Paragraph ID and Paragraph Matrix, respectively).
In the prediction phase, a new sentence ID is trained with random word samples from the sentence, but the softmax layer has its weights fixed. The sentence vector is updated in each step and the resulting sentence vector is the embedding for that sentence.
Comparison
Comparing both methods, the DM model has some technical advantages over the DBOW model:
- the DM model takes into account the word order, while the DBOW model doesn’t.
- the DBOW model does not use word vectors, which means that the semantics of the words are not preserved and it’s harder to detect similarities between words.
- due to the simpler architecture of the DBOW model, it takes many more steps to train to obtain accurate vectors.
The main drawback of the DM model is the time and the resources needed to generate an embedding, which are higher than with the DBOW model.
What approach produces better Sentence Embeddings? In the original paper, the authors say that the DM is “consistently better than” DBOW. However, recent studies reported that the DBOW approach is better for most tasks [2]. The implementation in Gensim of Doc2Vec [3] has the DBOW approach as the default algorithm, because it was found to have better results than the DM approach.
InferSent
InferSent is another Sentence Embedding method, presented by Facebook AI Research in 2018 [4], with an implementation and trained models available in Github [5].
It has some differences from the previous algorithm in the training process: instead of unsupervised learning to train a Language Model (LM) (a model that predicts the next word), it uses supervised learning to perform Natural Language Inference (NLI) (a model that predicts if an hypothesis, when compared to a premise, is true (entailment), false (contradiction) or undetermined (neutral)).
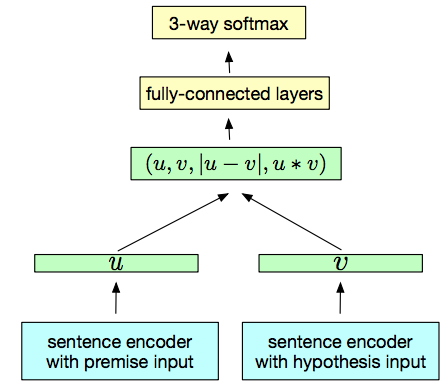
Figure 3 represents a generic training architecture for this approach. The u and v have shared weights, and are the Sentence Embeddings that we will obtain in the end.
In the training phase, the Sentence Embeddings of the premise and the hypothesis are concatenated, along with its element-wise product and its element-wise difference. The resulting vector is fed into multiple fully-connected layers, that finish with a 3-class softmax (the classes are entailment, contradiction or neutral).
What should be the architecture to create Sentence Embeddings? The authors tried different architectures, but here I will only describe the one that had the best results, that is the one implemented in InferSent: a BiLSTM with max pooling.
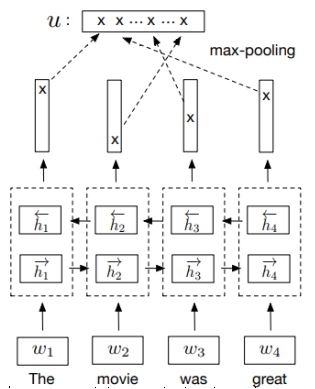
Figure 4 describes the architecture of the Bi-LSTM with max pooling. I will not explain thoroughly what an LSTM (Long Short-Term Network) is in this post (there’s great blog post about that in [6]).
In short, an LSTM is a neural network with the ability to remember previous inputs and use them in the computation of the next outputs (recurrent neural network). That is done by a hidden vector (h in Figure 8) that represents the memory of the current state of the input. This architecture contains a Bi-directional LSTM network, which means that two LSTM networks are applied: one takes care of the previous inputs to predict the output of the next step (forward LSTM), the other LSTM is reversed: it looks at the inputs from the end to the beginning, and tries to predict in that order (backwards LSTM).
The output vectors of both LSTM networks are then concatenated, and the final embedding is the maximum value over the dimension of the hidden units, as seen in Figure 4.
At the cost using supervised data for training and a complex recurrent neural network (RNN) architecture, this approach creates great Sentence Embeddings.
With the advent of the Transformers and BERT, another architecture became SOTA in 2019 - Sentence-BERT. Read part 3 to know more about it!
Thanks for sticking by!
References
- [1]: Quoc Le and Tomas Mikolov: “Distributed Representations of Sentences and Documents”, 2014; arXiv:1405.4053.
- [2]: Jey Han Lau and Timothy Baldwin: “An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding Generation”, 2016, Proceedings of the 1st Workshop on Representation Learning for NLP, Berlin, Germany, pp. 78–86; arXiv:1607.05368.
- [3]: Gensim - Doc2vec paragraph embeddings.
- [4]: Alexis Conneau, Douwe Kiela, Holger Schwenk, Loic Barrault: “Supervised Learning of Universal Sentence Representations from Natural Language Inference Data”, 2017; arXiv:1705.02364.
- [5]: InferSent implementation.
- [6]: Christopher Olah, Understanding LSTM Networks.